Introduction
Despite the state-of-the-art performance, DiTs can also be computationally expensive both in terms of memory and computational requirements. This becomes especially critical when applied with a large number of input tokens (e.g. high-resolution long video generation). To tackle these challenges and reduce the footprint of diffusion models, various research directions have emerged such as latent diffusion, step-distillation, caching, architecture-search, token reduction and region-based diffusion. Fewer techniques transfer readily from UNet-based pipelines to DiTs, whereas others often require novel formulations. Hence, DiT acceleration has been under-explored as of yet. Moreover, we note that "not all videos are created equal". Some videos contain high-frequency textures and significant motion content, whereas others are much simpler (e.g. with homogeneous textures or static regions). Having a diffusion process tailored specifically for each video generation can be beneficial in terms of realizing the best quality-latency trade-off.
Motivated by the above, we introduce Adaptive Caching (AdaCache) for accelerating video diffusion transformers. This approach requires no training and can seamlessly be integrated into a baseline video DiT at inference, as a plug-and-play component. The core idea of our proposal is to cache residual computations within transformer blocks (e.g. attention or MLP outputs) in a certain diffusion step, and reuse them through a number of subsequent steps, that is dependent on the video being generated. We do this by devising a caching schedule, i.e., deciding when-to-recompute-next whenever making a residual computation. This decision is guided by a distance metric that measures the rate-of-change between previously-stored and current representations. If the distance is high we would not cache for an extended period (i.e., #steps), to avoid reusing incompatible representations. We further introduce a Motion Regularization (MoReg) to allocate computations based on the motion content in the video being generated. This is inspired by the observation that high-moving sequences require more diffusion steps to achieve a reasonable quality. Altogether, our pipeline is applied on top of multiple video DiT baselines showing much-faster inference speeds without sacrificing generation quality.
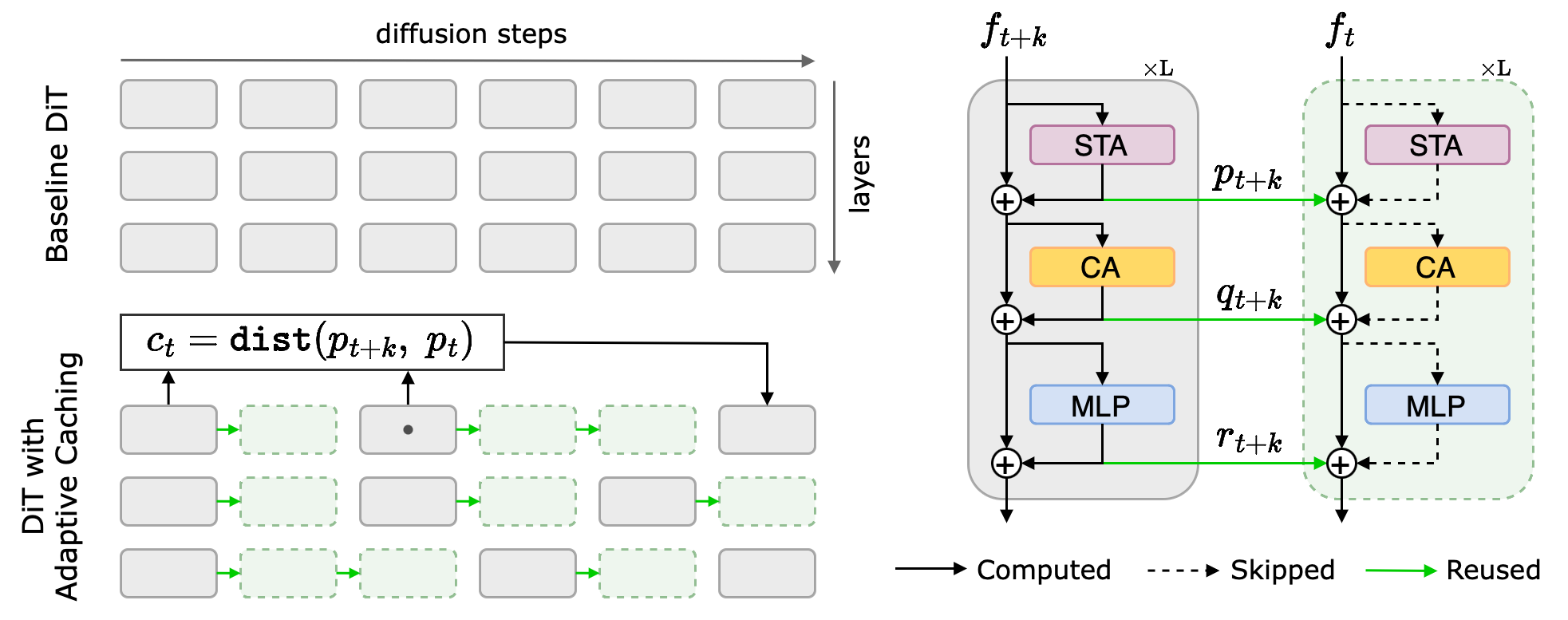
Overview of Adaptive Caching: (Left) During the diffusion process, we choose to cache residual computations within selected DiT blocks. The caching schedule is content-dependent, as we decide when to compute the next representation based on a distance metric (ct). This metric measures the rate-of-change from previously-computed (and, stored) representation to the current one, and can be evaluated per-layer or the DiT as a whole. Each computed residual can be cached and reused across multiple steps. (Right) We only cache the residuals (i.e., skip-connections) which amount to the actual computations (e.g. spatial-temporal/cross attention, MLP). The iteratively denoised representation (i.e., ft+k , ft) always gets updated either with computed or cached residuals.
Evaluation
Qualitative results
AdaCache shows a comparable generation quality, while being much-faster at inference. In fact, at extreme caching rates, it can achieve upto 4.49$\times$ speedup on-average (vs. 1.26$\times$ in Pyramid Attention Broadcast) on Open-Sora baseline for 720p-2s video generations. In most cases our generations are aligned well with the baseline in the pixel-space. Yet this is not a strict requirement, as the denoising process can deviate from that of the baseline, especially at higher caching rates. Still, AdaCache is faithful to the text prompt and is not affected by significant artifacts. A few qualitative examples from Open-Sora + AdaCache is shown below.
Comparison with prior-art
First, we note that AdaCache can achieve significantly-higher reduction rates (i.e., much-smaller absolute latency) compared to Pyramid Attention Broadcast (PAB). Also, AdaCache is more-stable across the whole latency curve, giving better quality-latency trade-offs. This is evident in both quantitative metrics (refer to the paper) and qualitative results (given below). Here, we compare 720p-2s video generations using Open-Sora, with reasonable speedups on a single A100 GPU: PAB w/ 1.66$\times$ speedup vs. AdaCache w/ 2.61$\times$ speedup.
Ablation: AdaCache vs. AdaCache (w/ MoReg)
We show a qualitative comparison of AdaCache and AdaCache (w/ MoReg), applied on top of Open-Sora baseline for 720p-2s (100-step) and 480p-2s (30-step) video generations. Here, we consider extreme caching rates. Despite giving a 4.69$\times$ (or, 2.24$\times$) speedup on a single A100 GPU, AdaCache can also introduce some inconsistencies over time (e.g. artifacts, motion, color). Motion Regularization helps avoid most of them by allocating more computations proportional to the amount of motion, still giving a 4.49$\times$ (or, 2.10$\times$) speedup.
Conclusion
In this paper, we introduced Adaptive Caching (AdaCache), a plug-and-play component that improves the the inference speed of video generation pipelines based on diffusion transformers, without needing any re-training. It caches residual computations, while also devising the caching schedule dependent on each video generation. We further proposed a Motion Regularization (MoReg) to utilize video information and allocate computations based on motion content, improving the quality-latency trade-off. We apply our contributions on multiple open-source video DiTs, showing comparable generation quality at a fraction of latency. We believe AdaCache is widely-applicable with minimal effort, helping democratize high-fidelity long video generation.
Citation
If you find this useful, please consider citing our work:
@article{adacache,
title={Adaptive Caching for Faster Video Generation with Diffusion Transformers},
author={Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S. Ryoo, and Tian Xie},
journal={arXiv preprint arXiv:2411.02397},
year={2024}
}